Optez pour une voie plus rapide et plus intelligente vers l'automatisation des tests C/C++ pilotée par l'IA. Découvrez comment >>

Livre blanc
Vous voulez un aperçu rapide de nos découvertes ? Consultez l’étude ci-dessous.
Avec la démocratisation des outils d'IA dans les tâches de programmation quotidiennes, l'utilisation de modèles de langage étendus (LLM) comme ChatGPT ou Copilot pour l'écriture automatisée de tests unitaires devient de plus en plus courante. Pour les équipes de développement, quel que soit leur stade de développement, il est essentiel d'analyser et d'évaluer comment optimiser l'utilisation des LLM lors de la création des tests, en comparant les outils LLM dédiés aux solutions d'IA propriétaires et à leurs combinaisons.
Cette étude évalue les performances et la qualité des tests unitaires générés par deux outils basés sur l'IA : Assistant de tests unitaires Parasoft Jtest (UTA) et GitHub Copilot. Plusieurs projets Java ont été sélectionnés comme exemples, pour lesquels une suite de tests unitaires a été générée selon la procédure documentée de chaque outil. Les tests générés ont ensuite été évalués à l'aide de plusieurs indicateurs, notamment la couverture, la qualité initiale des tests (par exemple, les erreurs de compilation ou la nécessité de corrections), les résultats d'exécution et le temps consacré à leur création.
Bien que les outils LLM purs comme Copilot facilitent l'exploitation de la puissance actuelle et croissante des LLM pour la génération de tests unitaires, ils souffrent de limitations intrinsèques et produisent des tests nécessitant de nombreuses corrections. Les outils qui effectuent leur propre analyse de code propriétaire pour générer des tests peuvent éviter ces problèmes et exceller dans le traitement en profondeur de grands volumes de code, aboutissant à des tests prêts à l'emploi. En combinant les atouts des deux types d'outils, Parasoft Jtest UTA offre des résultats supérieurs plus rapidement que Copilot ou LLM directement.
Nous avons sélectionné deux projets d'exemple pour évaluer les outils que nous avons choisis :
Pour Parabank, nous avons généré des tests pour l'ensemble du projet, mais étant donné l'importance du code source de libGDX, nous avons choisi de nous concentrer sur le package com.badlogic.gdx.math. Des tests ont été créés pour chaque classe concrète (à l'exclusion des interfaces et des classes abstraites) et pour toutes les méthodes accessibles (non déclarées privées).
Dans Visual Studio Code avec Copilot installé, nous avons demandé à Copilot de générer des tests au niveau des classes en utilisant le modèle gpt-4o et l'invite par défaut « /tests ». Le résultat a été accepté tel quel et enregistré à l'emplacement par défaut des tests dans le projet. Une fois tous les tests générés, les problèmes de compilation ont été corrigés, les tests ont été exécutés et la couverture de code ainsi que d'autres métriques ont été collectées.
En éclipse avec Jtest Parasoft Après l'installation, nous avons demandé à l'assistant de tests unitaires Jtest de générer une suite de tests pour tous les fichiers concernés. Cet assistant pouvant enrichir les tests générés avec LLM, nous avons effectué deux générations : une première avec les fonctionnalités LLM désactivées, puis une seconde avec LLM activé à l'aide du modèle gpt-4o. Les tests ont ensuite été exécutés et la couverture de code ainsi que d'autres métriques ont été collectées.
Nous avons priorisé les indicateurs que les équipes de développement recherchent pour évaluer un solution de test unitaire:
| Métrique | Copilote | Jtest UTA | Test UTA avec LLM |
|---|---|---|---|
| Tests générés | 342 tests dans 33 classes | 814 tests dans 49 classes | 776 tests dans 49 classes |
| Erreurs de compilation | 49 | 0 | 0 |
| Couverture de la ligne | 47 % | 74 % | 78 % |
| Taux de réussite de l'exécution | 86.5 % | 90.7 % | 96.4 % |
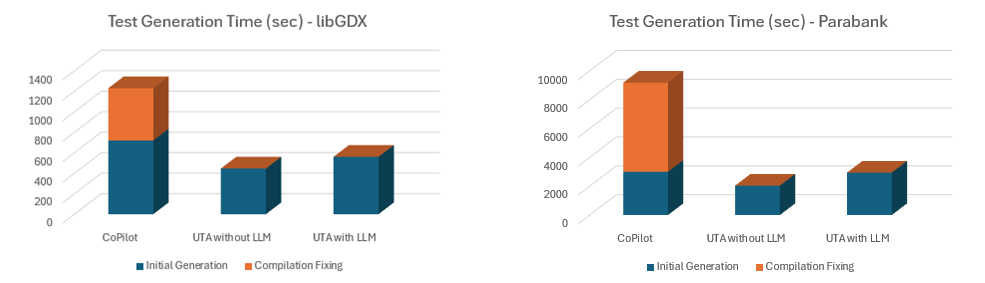
| Temps de création du test initial | 12m | 7m 26s | 9m 20s |
| Il est temps de régler les problèmes | 8m 30s | Pas d'issues | Pas d'issues |
| Temps total passé | 20m 30s | 7m 26s | 9m 20s |
| Temps par test | 3.6s | 0.5s | 0.7s |
Chaque fichier généré par Copilot contenait la déclaration du package après les importations, et ne pouvait donc pas être compilé. De plus, on a relevé trois importations manquantes, deux types d'arguments incorrects passés aux méthodes appelées dans le test, et un appel à une méthode inaccessible dans une assertion.
| Métrique | Copilote | Jtest UTA | Test UTA avec LLM |
|---|---|---|---|
| Tests générés | 659 tests dans 134 classes | 1151 tests dans 134 classes | 1090 tests dans 134 classes |
| Erreurs de compilation | 1048 | 0 | 0 |
| Couverture de la ligne | 56 % | 69 % | 69 % |
| Taux de réussite de l'exécution | 71.3 % | 86 % | 89 % |
| Temps de création du test initial | 50m | 34m | 49m |
| Il est temps de régler les problèmes | 1h 43m | Pas d'issues | Pas d'issues |
| Temps total passé | 2h 33m | 34m | 49m |
| Temps par test | 14s | 1.8s | 2.7s |
Une fois de plus, tous les fichiers créés par Copilot ont placé la déclaration du package à un emplacement incorrect. De plus, des tests ont été générés pour ce projet avec JUnit 5, alors que le classpath ne contenait que des bibliothèques JUnit 4. On a constaté des importations manquantes ou invalides, des appels à des méthodes ou constructeurs inexistants, des tentatives d'accès à des champs inaccessibles, des exceptions non gérées, la simulation de méthodes void et des paramètres incorrects passés aux méthodes.
Les principaux objectifs de l'adoption d'un outil de tests unitaires sont souvent les suivants :
Parasoft Jtest UTA génère plus rapidement et automatiquement davantage de tests qui compilent, réussissent et offrent une meilleure couverture. UTA propose également des fonctionnalités étendues pour la maintenance des tests : analyse du comportement à l’exécution et recommandations, comblement des lacunes de couverture, correction automatique des tests défaillants, analyse d’impact des tests, etc.
Étant donné que les tests générés avec Copilot ne compilent pas sans travail supplémentaire, nous avons suivi séparément le temps passé à corriger les problèmes de compilation afin d'illustrer l'effort supplémentaire que cela représente pour le processus.
Copilot ne génère les tests que pour une classe à la fois, et non par lots. Les développeurs doivent donc gérer manuellement le processus de génération des tests. Cela allonge le temps consacré à chaque fichier de test généré (cliquer sur l'action, attendre la fin du traitement par Copilot, accepter et enregistrer le résultat). Si l'on ajoute le temps de correction manuelle des erreurs de compilation, le temps total de génération est bien plus élevé.
Parasoft Jtest UTA traite l'ensemble du périmètre sélectionné par lots ; vous pouvez donc lancer la tâche et y revenir plus tard une fois qu'elle sera terminée.
En raison des limitations des LLM et des actions disponibles dans Copilot, le nombre de tests générés par méthode testée peut varier considérablement. Ceci engendre des incohérences et des lacunes dans la couverture des tests. Parasoft Jtest UTA, quant à lui, ne présente pas ces limitations et génère des tests de manière systématique, quelle que soit la taille de la classe ou de la méthode.
Certains facteurs, comme le taux de réussite/échec aux tests, peuvent influencer le taux de couverture final. Dans cette étude, nous n'avons pas veillé à ce que tous les tests soient réussis ; si nous l'avions fait, cela aurait pu modifier les chiffres de couverture finaux.


Pour que les tests générés soient utiles à la détection des bogues et des régressions, ils doivent être maintenus en état de réussite. Si un test généré ne s'exécute pas correctement, les développeurs doivent corriger ces erreurs avant de le valider. Ce processus prend du temps pour chaque test ; il est donc fortement préférable d'obtenir un taux de réussite/échec élevé pour un ensemble donné de tests générés.
Notre étude a révélé que les deux outils atteignaient un taux de réussite élevé, dépassant parfois les 90 %. Parasoft Jtest UTA a systématiquement affiché un taux de réussite supérieur grâce à son IA propriétaire qui analyse en profondeur le code testé, permettant ainsi des tests plus complets et mieux configurés. Lorsque les fonctionnalités LLM sont activées, les tests ayant échoué après leur création sont améliorés par LLM lors d'une étape de post-traitement. Concrètement, cela se traduit par un gain de temps considérable consacré à la correction des tests défaillants avant leur intégration au système de gestion de versions.
L'utilisation d'un outil de test unitaire basé sur LLM présente des limitations inhérentes dont il faut tenir compte. Tout d'abord, LLM est limité en jetons et payant. Par conséquent, les outils doivent choisir avec soin le contexte (code source, explications et autres informations) à transmettre à LLM. Comme LLM n'a pas accès à l'intégralité du code source, il formule des hypothèses qui doivent être corrigées ultérieurement. Cela entraîne des problèmes de compilation, des échecs de tests et des anomalies dans le code généré. Parasoft Jtest UTA, quant à lui, dispose d'un accès complet au code source et utilise sa propre analyse propriétaire basée sur l'IA pour optimiser la génération des tests. Ainsi, les tests sont construits et configurés avec une plus grande précision, même lorsque les fonctionnalités LLM sont désactivées.
Deuxièmement, les outils de modélisation du code (LLM) sont limités dans la quantité de code qu'ils peuvent générer par interaction. Avec Copilot, vous avez plus de chances d'obtenir des tests réussis pour une petite classe ou une classe simple que pour des classes très volumineuses. Il est possible d'obtenir de meilleurs résultats en analysant chaque méthode individuellement, mais cela demande beaucoup plus de temps et d'efforts manuels. Parasoft Jtest UTA analyse intégralement chaque méthode à tester, quelle que soit la taille du code source, ce qui permet d'obtenir des suites de tests plus complètes et cohérentes, avec une meilleure couverture et sans effort supplémentaire.
Troisièmement, les LLM ne peuvent pas exécuter les tests générés après leur création pour les améliorer à partir des résultats d'exécution réels. Les tests peuvent contenir des assertions incorrectes dues aux hypothèses formulées par le LLM, et des tests dupliqués peuvent être présents. Parasoft Jtest UTA exécute les tests après leur création afin de générer des assertions basées sur les données d'exécution réelles, d'optimiser les tests à conserver en fonction de votre stratégie de test (par exemple, l'optimisation de la couverture ou du taux de réussite d'exécution) et de les post-traiter pour apporter des améliorations supplémentaires.
Il convient également de noter que Parasoft Jtest UTA offre bien plus que le flux de travail de génération de tests que nous avons comparé ici. UTA peut également :
Les outils basés exclusivement sur les modèles linéaires logiques (LLM), comme Copilot, présentent indéniablement des atouts. Par exemple, ils excellent dans la compréhension de la fonction du code, au-delà de sa structure, et fournissent des noms et des valeurs pertinents dans le code généré. De plus, grâce à leur vaste base de données d'exemples de code, ils peuvent appréhender un large éventail de constructions et de modèles de programmation et trouver la solution optimale lors de l'utilisation de bibliothèques courantes. De nouveaux modèles sont régulièrement publiés, garantissant ainsi la mise à jour de ces outils.
Parasoft Jtest UTA, même sans intégration LLM, excelle dans la génération de suites de tests complètes et minimales couvrant la quasi-totalité des chemins d'exécution, même pour des bases de code volumineuses et complexes. UTA exécute les tests après leur création afin d'examiner la couverture, les données d'exécution et le comportement de l'application, générant ainsi des validations pertinentes et améliorant la stabilité des tests.
En activant l'intégration LLM dans Parasoft Jtest UTA, vous bénéficiez du meilleur des deux mondes : des tests complets, stables, lisibles et maintenables, générés rapidement et sans effort. Une fois les tests générés, UTA propose des actions intégrées et optimisées par l'IA pour les améliorer et les mettre à jour en fonction des modifications du code applicatif.
Prêt à plonger plus profondément ?


