Gehen Sie einen schnelleren, intelligenteren Weg zur KI-gestützten C/C++-Testautomatisierung. Erfahren Sie mehr >>

Whitepaper
Möchten Sie einen schnellen Überblick über unsere Ergebnisse erhalten? Sehen Sie sich die Studie unten an.
Da KI-Tools immer häufiger bei alltäglichen Programmieraufgaben eingesetzt werden, steigt auch die Verbreitung von Large Language Models (LLM)-Tools wie ChatGPT oder Copilot zur automatisierten Erstellung von Unit-Tests. Für Entwicklungsteams in allen Phasen ihrer Unit-Testing-Aktivitäten ist es daher sinnvoll zu prüfen und zu bewerten, wie LLMs bei der Testerstellung optimal genutzt werden können. Dies gelingt durch den Vergleich reiner LLM-Tools mit proprietären KI-Lösungen und deren Kombination.
Diese Studie bewertet die Leistungsfähigkeit und Qualität von Unit-Tests, die von zwei KI-gestützten Tools generiert wurden: Parasoft Jtest Unit Test Assistant (UTA) und GitHub Copilot. Es wurden mehrere Java-Beispielprojekte ausgewählt, für die jeweils eine Reihe von Unit-Tests mithilfe der dokumentierten Vorgehensweise der einzelnen Tools generiert wurde. Die generierten Tests wurden anschließend anhand verschiedener Metriken bewertet, darunter Testabdeckung, anfängliche Testqualität (z. B. Kompilierungsfehler oder erforderliche Korrekturen), Testausführungsergebnisse und der Zeitaufwand für die Testerstellung.
Obwohl reine LLM-Tools wie Copilot die Nutzung der aktuellen und wachsenden Leistungsfähigkeit von LLMs für die Unit-Test-Generierung vereinfachen, stoßen sie auch an ihre Grenzen und erzeugen Tests, die umfangreiche Nachbearbeitungen erfordern. Tools, die eine eigene proprietäre Codeanalyse zur Testgenerierung durchführen, vermeiden diese Probleme und zeichnen sich durch ihre Fähigkeit zur tiefgreifenden Verarbeitung großer Codemengen aus, wodurch sofort einsatzbereite Tests entstehen. Durch die Kombination der Stärken beider Tool-Typen liefert Parasoft Jtest UTA überlegene Ergebnisse schneller als Copilot oder LLM direkt.
Wir haben zwei Beispielprojekte ausgewählt, um unsere gewählten Werkzeuge zu evaluieren:
Für Parabank haben wir Tests für das gesamte Projekt generiert. Da libGDX jedoch eine große Codebasis ist, haben wir uns auf das Paket com.badlogic.gdx.math konzentriert. Es wurden Tests für jede konkrete Klasse (nicht für Schnittstellen oder abstrakte Klassen) und alle zugänglichen Methoden (die nicht als privat deklariert sind) erstellt.
In Visual Studio Code mit installiertem Copilot haben wir Copilot angewiesen, Tests auf Klassenebene mithilfe des gpt-4o-Modells und der Standardeingabeaufforderung „/tests“ zu generieren. Das Ergebnis wurde unverändert übernommen und im Standardverzeichnis für Tests im Projekt gespeichert. Nachdem alle Tests generiert waren, wurden Kompilierungsfehler behoben, die Tests ausgeführt und die Codeabdeckung sowie weitere Metriken erfasst.
In Eclipse mit Parasoft Jtest Nach der Installation haben wir den Jtest Unit Test Assistant angewiesen, eine Testsuite für alle relevanten Dateien gleichzeitig zu erstellen. Da der Unit Test Assistant die generierten Tests mit LLM erweitern kann, haben wir die Testgenerierung zweimal durchgeführt: einmal mit deaktivierten LLM-Funktionen und einmal mit aktiviertem LLM unter Verwendung des gpt-4o-Modells. Anschließend wurden die Tests ausgeführt und die Codeabdeckung sowie weitere Metriken erfasst.
Wir haben die Kennzahlen priorisiert, die Entwicklungsteams bei der Bewertung eines Produkts heranziehen. Lösung für Unit-Tests:
| Metrisch | Copilot | Jtest UTA | Jtest UTA mit LLM |
|---|---|---|---|
| generierte Tests | 342 Tests in 33 Klassen | 814 Tests in 49 Klassen | 776 Tests in 49 Klassen |
| Kompilierungsfehler | 49 | 0 | 0 |
| Leitungsabdeckung | 47% | 74% | 78% |
| Ausführungserfolgsquote | 86.5% | 90.7% | 96.4% |
| Erstellungszeitpunkt des ersten Tests | 12m | 7m 26s | 9m 20s |
| Zeit, die Probleme zu beheben | 8m 30s | Keine Probleme | Keine Probleme |
| Gesamte aufgewendete Zeit | 20m 30s | 7m 26s | 9m 20s |
| Zeit pro Test | 3.6er-Jahre | 0.5er-Jahre | 0.7er-Jahre |
Alle von Copilot erzeugten Dateien enthielten die Paketdeklaration nach den Importen und ließen sich daher nicht kompilieren. Zusätzlich gab es drei Fälle fehlender Importe, zwei Fälle mit falschen Argumenttypen, die an im Test aufgerufene Methoden übergeben wurden, und einen Aufruf einer nicht zugänglichen Methode in einer Assertion.
| Metrisch | Copilot | Jtest UTA | Jtest UTA mit LLM |
|---|---|---|---|
| generierte Tests | 659 Tests in 134 Klassen | 1151 Tests in 134 Klassen | 1090 Tests in 134 Klassen |
| Kompilierungsfehler | 1048 | 0 | 0 |
| Leitungsabdeckung | 56% | 69% | 69% |
| Ausführungserfolgsquote | 71.3% | 86% | 89% |
| Erstellungszeitpunkt des ersten Tests | 50m | 34m | 49m |
| Zeit, die Probleme zu beheben | 1h 43m | Keine Probleme | Keine Probleme |
| Gesamte aufgewendete Zeit | 2h 33m | 34m | 49m |
| Zeit pro Test | 14er-Jahre | 1.8er-Jahre | 2.7er-Jahre |
Erneut platzierten alle von Copilot erstellten Dateien die Paketdeklaration an einer ungültigen Stelle. Zudem wurden für dieses Projekt Tests mit JUnit 5 erstellt, obwohl sich im Klassenpfad des Projekts ausschließlich JUnit-4-Bibliotheken befanden. Es traten fehlende oder ungültige Importe, Aufrufe nicht existierender Methoden oder Konstruktoren, Zugriffsversuche auf nicht zugängliche Felder, unbehandelte Ausnahmen, das Mocken von Methoden ohne Parameter und die Übergabe falscher Parameter an Methoden auf.
Zu den Hauptzielen bei der Einführung eines Unit-Testing-Tools gehören häufig:
Parasoft Jtest UTA generiert schneller mehr Tests, die kompilieren, erfolgreich durchlaufen werden und eine bessere Testabdeckung aufweisen. UTA bietet zudem mehr Funktionen zur Testwartung, wie die Analyse des Laufzeitverhaltens und die Bereitstellung von Empfehlungen, das Schließen von Abdeckungslücken, die automatische Behebung fehlerhafter Tests, die Durchführung von Testauswirkungsanalysen und vieles mehr.
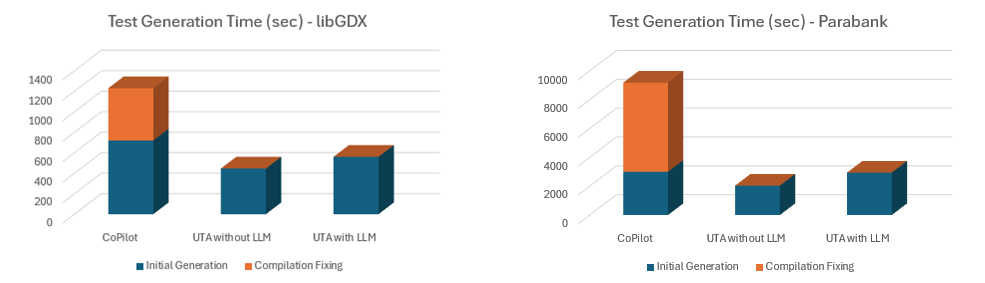
Da mit Copilot generierte Tests ohne zusätzlichen Aufwand nicht kompilieren, haben wir die für die Behebung von Kompilierungsproblemen aufgewendete Zeit separat erfasst, um zu veranschaulichen, wie viel Aufwand dies dem Prozess hinzufügt.
Copilot generiert Tests nur für jeweils eine Klasse und nicht als Batch, weshalb Entwickler den Testgenerierungsprozess selbst steuern müssen. Dies verlängert die Bearbeitungszeit für jede generierte Testdatei (Klicken der Aktion, Warten auf den Abschluss durch Copilot, Akzeptieren und Speichern des Ergebnisses). Berücksichtigt man zusätzlich die Zeit für die manuelle Behebung von Kompilierungsfehlern, ist die gesamte Generierungszeit deutlich höher.
Parasoft Jtest UTA verarbeitet den gesamten ausgewählten Bereich als Batch, sodass Sie den Auftrag starten und später zurückkehren können, wenn er abgeschlossen ist.
Aufgrund der Einschränkungen von LLMs und der in Copilot verfügbaren Aktionen kann die Anzahl der generierten Tests pro zu testender Methode stark variieren. Dies führt zu Inkonsistenzen und Lücken in der Testabdeckung. Parasoft Jtest UTA weist diese Einschränkungen nicht auf und generiert unabhängig von der Klassen- oder Methodengröße konsistent Tests.
Einige Faktoren, wie beispielsweise das Verhältnis von bestandenen zu nicht bestandenen Tests, können die endgültige Testabdeckung beeinflussen. In dieser Studie haben wir nicht darauf geachtet, dass alle Tests erfolgreich sind; hätten wir dies getan, könnte dies die endgültigen Testabdeckungswerte beeinflussen.


Damit generierte Tests zur Erkennung von Fehlern und Regressionen nützlich sind, müssen sie stets erfolgreich ausgeführt werden. Falls generierte Tests nicht ordnungsgemäß laufen, sollten Entwickler diese Fehler beheben, bevor sie die Tests einchecken. Dieser Prozess kostet zusätzliche Zeit für jeden Test, daher ist ein hohes Verhältnis von erfolgreichen zu fehlgeschlagenen Tests für einen gegebenen Satz generierter Tests äußerst wünschenswert.
In unserer Studie stellten wir fest, dass beide Tools eine hohe Erfolgsquote von teilweise über 90 % erreichten. Parasoft Jtest UTA erzielte durchweg eine höhere Erfolgsquote, da es eine eigene proprietäre KI für eine tiefgehende Codeanalyse nutzt, was zu vollständigeren und besser konfigurierten Tests führt. Sind die LLM-Funktionen aktiviert, werden nach der Erstellung fehlgeschlagene Tests in einem Nachbearbeitungsschritt mithilfe von LLM weiter verbessert. In der Praxis bedeutet dies weniger Zeitaufwand für die Behebung fehlgeschlagener Tests vor deren Einchecken in die Versionskontrolle.
Bei der Verwendung von LLM-basierten Unit-Testing-Tools sind systembedingte Einschränkungen zu beachten. Erstens ist LLM tokenbegrenzt und kostenpflichtig. Daher müssen Tools den Kontext (Quellcode, Erklärungen und weitere Informationen), der an LLM gesendet wird, sorgfältig auswählen. Da LLM keinen Zugriff auf die vollständige Codebasis hat, trifft es Annahmen, die später korrigiert werden müssen. Dies führt zu Kompilierungsproblemen, fehlgeschlagenen Tests und fehlerhaftem generiertem Code. Parasoft Jtest UTA hingegen hat vollen Zugriff auf den Quellcode und nutzt eine eigene, proprietäre KI-basierte Analyse zur Testgenerierung. Dadurch werden Tests präziser erstellt und konfiguriert, selbst wenn LLM-Funktionen deaktiviert sind.
Zweitens sind LLMs in der Menge an Code, die sie pro Interaktion generieren können, begrenzt. Mit Copilot erhalten Sie eher vollständig bestandene Tests für kleine oder einfache Klassen als für sehr große. Sie können bessere Ergebnisse erzielen, indem Sie jede Methode einzeln testen, dies ist jedoch deutlich zeitaufwändiger und erfordert mehr manuellen Aufwand. Parasoft Jtest UTA analysiert jede zu testende Methode vollständig, unabhängig von der Größe der Codebasis. Dies führt zu umfassenderen und konsistenteren Testsuiten mit besserer Abdeckung und ohne zusätzlichen Aufwand.
Drittens können LLMs generierte Tests nach ihrer Erstellung nicht ausführen, um sie anhand realer Laufzeitergebnisse zu verbessern. Tests können aufgrund von Annahmen des LLM fehlerhafte Zusicherungen enthalten, und es können doppelte Tests vorhanden sein. Parasoft Jtest UTA führt Tests nach ihrer Erstellung aus, um Zusicherungen auf Basis realer Laufzeitdaten zu generieren, die beizubehaltenden Tests gemäß Ihrer gewählten Teststrategie (z. B. Testabdeckung oder Optimierung des Ausführungserfolgs) zu optimieren und sie anschließend weiter zu verbessern.
Es ist außerdem erwähnenswert, dass Parasoft Jtest UTA weit mehr kann als den hier verglichenen Testgenerierungs-Workflow. UTA kann außerdem:
Reine LLM-basierte Tools wie Copilot haben zweifellos ihre Stärken. Sie verstehen beispielsweise neben der Struktur auch den Zweck von Code und generieren aussagekräftige Namen und Werte. Da sie auf eine große Datenbank mit Beispielcode zurückgreifen können, erkennen sie zudem eine Vielzahl von Codierungskonstrukten und -mustern und finden bei der Interaktion mit bekannten Bibliotheken die optimale Lösung. Regelmäßig werden neue Modelle veröffentlicht, sodass diese Tools stets aktuell sind.
Parasoft Jtest UTA generiert, auch ohne LLM-Integration, sehr gut vollständige und minimierte Testsuiten, die nahezu alle Ausführungspfade abdecken – selbst bei großen und komplexen Codebasen. UTA führt die Tests nach ihrer Erstellung aus, um Testabdeckung, Laufzeitdaten und Anwendungsverhalten zu analysieren und so echte Validierungen zu generieren und die Teststabilität zu verbessern.
Durch die Aktivierung der LLM-Integration in Parasoft Jtest UTA profitieren Sie von den Vorteilen beider Welten. Die Tests sind vollständig, stabil, lesbar und wartungsfreundlich – und werden schnell und mit minimalem Aufwand generiert. Nach der Testgenerierung bietet UTA sowohl integrierte als auch KI-gestützte Aktionen zur Verbesserung und Aktualisierung der Tests bei Änderungen im Anwendungscode.
Bereit, tiefer einzutauchen?


