Tome un camino más rápido e inteligente hacia la automatización de pruebas C/C++ impulsada por IA. Descubra cómo >>

White Paper
¿Quieres echar un vistazo rápido a lo que descubrimos? Consulta el estudio a continuación.
A medida que las herramientas de IA se vuelven más comunes en las tareas cotidianas de programación, se hace cada vez más común usar herramientas de Modelos de Lenguaje Largos (LLM), como ChatGPT o Copilot, para escribir pruebas unitarias de forma automatizada. Para los equipos de desarrollo, en todas las etapas de sus pruebas unitarias, es valioso revisar y evaluar cómo aprovechar al máximo los LLM durante la creación de pruebas, comparando las herramientas LLM puras con las soluciones de IA propietarias y la combinación de ambas.
Este estudio evalúa el rendimiento y la calidad de las pruebas unitarias generadas por dos herramientas habilitadas para IA: Asistente de pruebas unitarias (UTA) de Parasoft Jtest y GitHub Copilot. Se seleccionaron varios proyectos Java de ejemplo para los cuales se generó un conjunto de pruebas unitarias utilizando el proceso documentado de cada herramienta. Las pruebas generadas se evaluaron utilizando diversas métricas, como la cobertura, la calidad inicial de las pruebas (por ejemplo, errores de compilación o si se requirieron correcciones), los resultados de la ejecución de las pruebas y el tiempo dedicado a crearlas.
Si bien las herramientas LLM puras como Copilot facilitan el aprovechamiento de la potencia actual y creciente de los LLM para la generación de pruebas unitarias, también presentan limitaciones inherentes y generan pruebas que requieren una gran cantidad de correcciones. Las herramientas que realizan su propio análisis de código propietario para generar pruebas pueden evitar estos problemas y destacar en el procesamiento profundo de grandes cantidades de código, lo que resulta en pruebas listas para usar. Al combinar las ventajas de ambos tipos de herramientas, Parasoft Jtest UTA produce resultados superiores con mayor rapidez que Copilot o LLM directamente.
Seleccionamos dos proyectos de ejemplo para evaluar las herramientas elegidas:
Para Parabank, generamos pruebas para todo el proyecto, pero dado que libGDX es una base de código extensa, optamos por centrarnos en el paquete com.badlogic.gdx.math. Se crearon pruebas para cada clase concreta (no interfaces ni clases abstractas) y todos los métodos accesibles (no declarados privados).
En Visual Studio Code con Copilot instalado, le solicitamos que generara pruebas a nivel de clase usando el modelo gpt-4o y el indicador predeterminado "/tests". El resultado se aceptó tal cual y se guardó en la ubicación predeterminada para pruebas en el proyecto. Una vez generadas todas las pruebas, se solucionaron los problemas de compilación, se ejecutaron las pruebas y se recopilaron la cobertura de línea y otras métricas.
En Eclipse con Prueba J de Parasoft Una vez instalado, solicitamos al Asistente de Pruebas Unitarias de Jtest que creara un conjunto de pruebas para todos los archivos dentro del alcance simultáneamente. Dado que el Asistente de Pruebas Unitarias puede mejorar las pruebas generadas con LLM, generamos las pruebas dos veces: una con las funciones de LLM deshabilitadas y otra con LLM habilitado mediante el modelo gpt-4o. A continuación, se ejecutaron las pruebas y se recopilaron la cobertura de línea y otras métricas.
Priorizamos las métricas que los equipos de desarrollo buscan al evaluar un solución de pruebas unitarias:
| Métrico | Copilot | Prueba JTA | Jtest UTA con LLM |
|---|---|---|---|
| Pruebas generadas | 342 pruebas en 33 clases | 814 pruebas en 49 clases | 776 pruebas en 49 clases |
| Errores de compilación | 49 | 0 | 0 |
| Cobertura de línea | 47% | 74% | 78% |
| Tasa de éxito de ejecución | 86.5% | 90.7% | 96.4% |
| Hora de creación de la prueba inicial | 12m | 7m 26s | 9m 20s |
| Es hora de solucionar los problemas | 8m 30s | Sin problemas | Sin problemas |
| Tiempo total empleado | 20m 30s | 7m 26s | 9m 20s |
| Tiempo por prueba | Años 3.6 | Años 0.5 | Años 0.7 |
Todos los archivos producidos por Copilot contenían la declaración del paquete después de las importaciones, por lo que no se compilaron. Además, se registraron tres casos de importaciones faltantes, dos tipos de argumentos incorrectos pasados a métodos llamados en la prueba y una llamada a un método inaccesible en una aserción.
| Métrico | Copilot | Prueba JTA | Jtest UTA con LLM |
|---|---|---|---|
| Pruebas generadas | 659 pruebas en 134 clases | 1151 pruebas en 134 clases | 1090 pruebas en 134 clases |
| Errores de compilación | 1048 | 0 | 0 |
| Cobertura de línea | 56% | 69% | 69% |
| Tasa de éxito de ejecución | 71.3% | 86% | 89% |
| Hora de creación de la prueba inicial | 50m | 34m | 49m |
| Es hora de solucionar los problemas | 1h 43m | Sin problemas | Sin problemas |
| Tiempo total empleado | 2h 33m | 34m | 49m |
| Tiempo por prueba | Años 14 | Años 1.8 | Años 2.7 |
Una vez más, todos los archivos creados por Copilot colocaron la declaración del paquete en una ubicación no válida. Además, se crearon pruebas para este proyecto con JUnit 5, a pesar de que el proyecto solo contaba con bibliotecas de JUnit 4 en la ruta de clases. Se observaron casos de importaciones faltantes o no válidas, llamadas a métodos o constructores inexistentes, intentos de acceso a campos inaccesibles, excepciones no controladas, simulaciones de métodos vacíos y parámetros incorrectos pasados a los métodos.
A menudo, los objetivos principales de adoptar una herramienta de pruebas unitarias incluyen:
Parasoft Jtest UTA genera más pruebas listas para usar, que se compilan, superan y ofrecen una mejor cobertura. UTA ofrece más funciones para el mantenimiento de pruebas, como analizar el comportamiento en tiempo de ejecución y ofrecer recomendaciones, cubrir brechas de cobertura, corregir automáticamente pruebas fallidas, realizar análisis de impacto de pruebas y más.
Dado que las pruebas generadas con Copilot no se compilan sin trabajo adicional, rastreamos por separado el tiempo dedicado a solucionar problemas de compilación para ilustrar cuánto esfuerzo esto agrega al proceso.
Copilot también genera pruebas solo para una clase a la vez, no por lotes, por lo que los desarrolladores deben controlar el proceso de generación de pruebas. Esto aumenta el tiempo dedicado a generar cada archivo de prueba (hacer clic en la acción, esperar a que Copilot termine, aceptar y guardar el resultado). Si a esto le sumamos el tiempo de corrección manual de los problemas de compilación, el tiempo total de generación es mucho mayor.
Parasoft Jtest UTA procesa todo el alcance seleccionado como un lote, por lo que puede comenzar el trabajo y volver más tarde cuando esté completo.
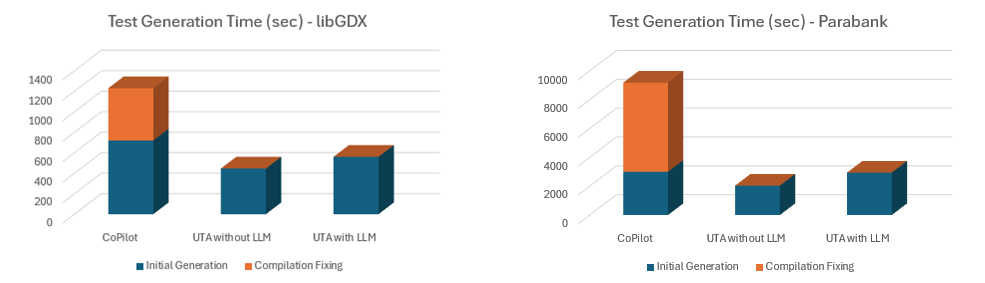
Debido a las limitaciones de los LLM y las acciones disponibles en Copilot, el número de pruebas generadas por cada método bajo prueba puede variar considerablemente. Esto genera inconsistencias y lagunas en la cobertura. Parasoft Jtest UTA no presenta estas limitaciones y genera pruebas consistentemente, independientemente de la clase o el tamaño del método.
Algunos factores, como la tasa de aprobación/reprobación de las pruebas, pueden afectar la tasa de cobertura final. En este estudio, no dedicamos tiempo a asegurar que el 100 % de las pruebas aprobaran; si lo hubiéramos hecho, esto podría afectar las cifras de cobertura final.


Para que las pruebas generadas sean útiles para detectar errores y regresiones, deben mantenerse en buen estado. Si las pruebas generadas no se ejecutan correctamente, los desarrolladores deben corregir estos fallos antes de confirmarlas. Este proceso requiere tiempo adicional para cada prueba, por lo que es altamente preferible una mayor tasa de éxito/fallo para un conjunto determinado de pruebas generadas.
En nuestro estudio, descubrimos que ambas herramientas lograron una alta tasa de éxito, en algunos casos superior al 90 %. Parasoft Jtest UTA obtuvo una tasa de éxito consistentemente más alta gracias a que utiliza su propia IA para un análisis profundo del código bajo prueba, lo que resulta en pruebas más completas y configuradas correctamente. Al habilitar las funciones LLM, las pruebas que fallan después de su creación se mejoran aún más mediante LLM en un paso de posprocesamiento. En la práctica, esto se traduce en menos tiempo dedicado a corregir las pruebas fallidas antes de enviarlas al control de código fuente.
Existen limitaciones inherentes que deben tenerse en cuenta al usar una herramienta de pruebas unitarias basada en LLM. En primer lugar, LLM tiene un límite de tokens y un precio. Esto significa que las herramientas deben seleccionar cuidadosamente el contexto (código fuente, explicaciones y otra información) que se enviará a LLM. Dado que LLM no tiene acceso a todo el código base, realiza suposiciones que deben corregirse posteriormente. Esto genera problemas de compilación, pruebas fallidas y errores en el código generado. Parasoft Jtest UTA tiene acceso completo al código fuente y utiliza su propio análisis patentado basado en IA para impulsar la generación de pruebas, lo que permite que las pruebas se creen y configuren con mayor precisión incluso con las funciones de LLM deshabilitadas.
En segundo lugar, los LLM tienen una capacidad limitada de generar código por interacción. Con Copilot, es más probable obtener pruebas completas que aprueben una clase pequeña o simple que una clase muy grande. Se pueden obtener mejores resultados al analizar cada método, pero esto requiere mucho más tiempo y esfuerzo manual. Parasoft Jtest UTA analiza a fondo cada método a probar, independientemente del tamaño de la base de código, lo que resulta en conjuntos de pruebas más completos y consistentes, con mejor cobertura y sin esfuerzo adicional.
En tercer lugar, los LLM no pueden ejecutar pruebas generadas tras su creación para mejorarlas con base en resultados de ejecución reales. Las pruebas pueden contener afirmaciones incorrectas basadas en suposiciones del LLM, y puede haber pruebas duplicadas. Parasoft Jtest UTA ejecuta pruebas tras su creación para generar afirmaciones basadas en datos reales de tiempo de ejecución, optimizar las pruebas que se deben conservar según la estrategia de prueba elegida, como la optimización de la cobertura o el éxito de la ejecución, y las posprocesa para realizar mejoras adicionales.
También cabe destacar que Parasoft Jtest UTA ofrece muchas más funciones que el flujo de trabajo de generación de pruebas que hemos comparado aquí. UTA también puede:
Las herramientas basadas en LLM puro, como Copilot, sin duda tienen sus puntos fuertes. Por ejemplo, son eficaces para comprender el propósito del código, además de su estructura, y proporcionan nombres y valores adecuados en el código generado. Además, al contar con una extensa base de datos de código de ejemplo, pueden comprender una amplia gama de construcciones y patrones de codificación y encontrar la mejor solución al interactuar con bibliotecas conocidas. La publicación regular de nuevos modelos mantiene estas herramientas actualizadas.
Parasoft Jtest UTA, incluso sin integración con LLM, es muy eficaz para generar un conjunto completo y reducido de pruebas que cubren prácticamente todas las rutas de ejecución, incluso con bases de código extensas y complejas. UTA ejecuta pruebas tras su creación para examinar la cobertura, los datos de ejecución y el comportamiento de la aplicación, generando así validaciones reales y mejorando la estabilidad de las pruebas.
Al habilitar la integración de LLM en Parasoft Jtest UTA, obtiene lo mejor de ambos mundos. Las pruebas son completas, estables, legibles y fáciles de mantener, y se generan rápidamente y con el mínimo esfuerzo. Una vez generadas, UTA ofrece acciones integradas y optimizadas con IA para mejorarlas y actualizarlas a medida que cambia el código de la aplicación.
¿Listo para sumergirte más profundamente?


